[update: you can see an implementation here ]
Index
- Introduction
- Strengths of Gossip
- Applications
- Examples
- How do they work?
- Types of Gossip
- Removed state
- Modelling Rumour Mongering
- Strategies for spreading the gossip
- How to measure good epidemics
- The peer sampling service
- Caveats
- References
Introduction
A primary use of gossip is for information diffusion: some event occurs, and our goal is to spread the word [3]
They are a communication protocol, a way of multicast messages inspired by:
- Epidemics
- Human gossip
- Social networks
Trying to squash a rumor is like trying to unring a bell.
~Shana Alexander
Rumours in society travel at a great speed and reach almost every member of the community, and which is even better without needing a central coordinator.
It is a basic result of epidemic theory that simple epidemics eventually infect the entire population. The theory also shows that starting with a single infected site this is achieved in expected time proportional to the log of the population size. [1]
Gossip protocols try to solve the problem of Multicast, that is, we want to communicate a message to all the nodes in the network. Although as we’ll see, each node doesn’t send the message to all nodes, each node sends the message to only a few of the nodes.
Strengths of Gossip
- Scalable
They are scalable because in general, it takes O(logN) rounds to reach all nodes, where N is number of nodes [17]. Also each node sends only a fixed number of messages independent of the number of nodes in the network. A node does not wait for acknowledgments, and it doesn’t take any recovery action if an acknowledgment does not arrive. [16]. A system can easily scale to millions of processes. - Fault-tolerance
They have the ability to operate in networks with irregular and unknown connectivity [3]. They work really well in these situations because as we’re going to se a node shares the same information several times to different nodes, so if a node is not accesible the information is shared anyways through a different node. In other words there are many routes by which information can flow from its source to its destinations. - Robust
No node plays a specific role in the network, so a failed node will not prevent other nodes from continuing sending messages [16].
Each node can join or leave whenever it pleases without seriously disrupting the system’s overall quality of service [18].They’re not robust in all circumstances, for example, if the problem is related to a malfunctioning nodes or malicious then gossip is not robust at all. For example that happened with Amazon s3, they had an outage in July, 2008, because the information that was being shared through a gossip protocol, had a single bit corrupted such that the message was still intelligible, so it was spread, but system state information was incorrect, at the end they had to shutdown the whole system and fixed the state they had on disk. - Convergent consistency.
Gossip protocols achieve exponentially rapid spread of information and, therefore, converge exponentially quickly to a globally consistent state after a new event occurs, in the absence of additional events. Propagate any new information to all nodes that will be affected by the information within time logarithmic in the size of the system.
- Extremely decentralized
Gossip offers an extremely decentralized form of information discovery, and its latencies are often acceptable if the information won’t actually be used immediately. [3] - Little code and complexity

Applications
- Database replication
- Information dissemination
- Cluster membership
- Failure Detectors
- Overlay Networks
- Aggregations (e.g calculate average, sum, max)
Examples
- Riak uses a gossip protocol to share and communicate ring state and bucket properties around the cluster.
- In CASSANDRA nodes exchange information using a Gossip protocol about themselves and about the other nodes that they have gossiped about, so all nodes quickly learn about all other nodes in the cluster. [9]
- Dynamo employs a gossip based distributed failure detection and membership protocol. It propagates membership changes and maintains an eventually consistent view of membership. Each node contacts a peer chosen at random every second and the two nodes efficiently reconcile their persisted membership change histories [6].
Dynamo gossip protocol is based on a scalable and efficient failure detector introduced by Gupta and Chandra in 2001 [8] - Consul uses a Gossip protocol called SERF for two purposes [10]:
– discover new members and failures
– reliable and fast event broadcasts for events like leader election.
The Gossip protocol used in Consul is called SERF and is based on “SWIM: Scalable Weakly-consistent Infection-style Process Group Membership Protocol” - Amazon s3 uses a Gossip protocol to spread server state to the system [8].
How do they work?
 Gossip protocols are very simple conceptually and very simple to code. The basic idea behind them is this: A node wants to share some information to the other nodes in the network. Then periodically it selects randomly a node from the set of nodes and exchanges the information. The node that receives the information does exactly the same thing. The information is periodically send to N targets, N is called fanout.
Gossip protocols are very simple conceptually and very simple to code. The basic idea behind them is this: A node wants to share some information to the other nodes in the network. Then periodically it selects randomly a node from the set of nodes and exchanges the information. The node that receives the information does exactly the same thing. The information is periodically send to N targets, N is called fanout.
- Cycle
Number of rounds to spread a rumour - Fanout
Number of nodes a node gossips with in each cycle. When a node wants to broadcast a message, it selects t nodes from the system at random and sends the message to them.
With fanout = 1, then O(Log N) cycles are necessary for the update to reach all the nodes [4].
In most implementations a node has a partial view of the nodes, in order to keep a completed view of the nodes, each node should have stored the whole list and it should be able to update the list constantly, for example if a node is inaccessible it should be removed from the set in each other node, which is a very complex task. [5]
There have been many attempts to formally define gossip but there is no standard definition [13]
In general we can observe the followings properties [4] [13]:
- Node selection must be random, or at least guarantee enough peer diversity.
- Only local information is available at all nodes (nodes are not aware of the state of the whole system and act based on local knowledge).
- Communication is round-based (periodic).
- Transmission and processing capacity per round is limited.
- All nodes run the same protocol.
But as I said there is no standard definition, and according to Birman[3], a gossip protocol is one who satisfies the following properties:
- The core of the protocol involves periodic, pairwise, inter-
process interactions - The information exchanged during these interactions is of
(small) bounded size - When nodes interact, the state of one or both changes in a
way that reflects the state of the other. For example, if A pings B just to measure the round-trip-time between them, it isn’t a gossip interaction. - Reliable communication is not assumed
- The frequency of the interactions is low compared to typical
message latencies, so that the protocol costs are negligible - There is some form of randomness in the peer selection. Peer selection might occur within the full node set, or might be performed in a smaller set of neighbours.
Both lists are similar although this one is more restricted, for example the previous definition doesn’t mention anything about sharing the state between the nodes.
They’re randomized algorithms as they select the node to which send the message randomly. All Gossip protocols rely on a service to provide every node with peers to exchange information with. This service is call “the peer sampling service” [7] which we’ll see later in details.
They’re not deterministic, as we’ve mentioned before they’re randomised , so it’s not possible to mimic the behaviour, one run of the algorithm is different from the other. The reliability level can be very high; unless malicious faults are considered, outcomes with probability 1 are common [3].
For some type of gossip (complex epidemics) we only can have probabilistic guarantees that can be tune with some parameters like the cycle, fanout, etc. You can see a simulator here
A bit of history (Epidemic Algorithms for Replicated Database Maintenance)
The paper “Epidemic Algorithms for Replicated Database Maintenance” [1] (1987) is considered to be seminal.
It’s not clear when was the first time Gossip protocols were first used in Distributed systems [3], it is believed that it was in 1987 as described in the paper “Epidemic Algorithms for Replicated Database Maintenance” [1], although information dissemination was used before that [14] and before that Baker and Shostak [15] described a gossip protocol.
The problem they were trying to solve can be summarize:
- They were trying to build a directory, a look-up database.
- The network was unreliable.
- Each update is injected at a single site and propagated to all sites or substituted by a later update.
- Database replicated at thousands of nodes.
- Replicas become consistent after no more new updates.
States of a node
Gossip protocols literature have adopted some terms from the epidemiology literature [1], namely the SIR model [2]:
- Infective.
A node with an update it is willing to share. - Susceptible.
A node that has not received the update yet (It is not infected). - Removed.
A node that has already received the update but it is not willing to share it.
Removed is trickier than rest. It’s not easy to determine when a node should stop sharing the info/update. Ideally a node should stop sharing the update when all the nodes is linked with have the update. But that would mean that node would have to have knowledge of the status of the other nodes.
Later we will see different algorithms, approaches to mark a node as Removed.
Analyzed algorithms
They analysed 3 methods for spreading the updates:
- Direct mail
The one they had in place initially, each new update is immediately emailed from its entry site to all other sites but it presented several problems:- The sending node was a bottleneck O(n).
- Each update was propagated to all the nodes, so each node had to know all the nodes in the system.
- Messages could be discarded when a node was unresponsive for a long time or due to queue overflow.
- Anti-entropy
Every site regularly chooses another site at random and by exchanging database contents with it resolves any differences between the two. It was used together with direct mail or Rumour Mongering and run to correct undelivered updates, kind of a backup system.
Image that using Direct Mail an updated did not arrive to a node, Anti-entropy was supposed to fix that. - Rumor mongering.
Sites are initially ignorant; when a site receives a new update it becomes a “hot rumor”; while a site holds a hot rumor. It periodically chooses another site at random and ensures that the other site has seen the update. when a site has tried to share a hot rumor with too many sites that have already seen it, the site stops treating the rumor as hot and retains the update without propagating
it further.
It spreads updates fast with low traffic network, but as we’re going to see we only have probabilistic guarantees that an update will arrive to all the nodes.
Last two algorithms are epidemic/gossip algorithms and are remained as the two types of Gossip protocols (for some authors [3] Aggregation is another type too). So let’s see a more generic description of these types.
Types of Gossip
- Anti-entropy (SI model)
Simple epidemics. A node is always susceptible or infective. - Rumor Mongering (SIR model)
Complex epidemics. A node can be susceptible, infective or removed.
The name of anti-entropy is because the algorithm was used to reduce the entropy in the replicas, or in other words, to increase similarity between them.
In Anti-entropy (SI model) a node that has an infective info is trying to share it in every cycle. A node not only shares the last update but the whole database, there are some techniques like checksum, recent update list, merkle trees, etc that allow a node to know if there are any differences between the two nodes before sending the database, it guarantees, eventual, perfect dissemination.
There is not termination, so It sends an unbounded number of messages.
Rumor Mongering cycles can be more frequent than anti-entropy cycles because they require fewer resources, as the node only send the new update or a list of infective updates. Rumour mongering spreads updates fast with low traffic network.
A rumor at some point is marked as removed and it’s not shared any more, because of that, the number of messages is bounded and there is some chance that the update will not reach all the sites, although this probability can be made arbitrarily small as we’ll see later. First let’s see how to decide when a node should be in state «removed».
Removed State / Loss of interest
(based on a presentation from Mark Jelasity [16]).
- Removal algorithms to decide if a node should be in “Removed” state:
- Coin/random.
Removed with probability 1/k after each unsuccessful attempt. - Counter.
Removed after k unnecessary contacts.
- Coin/random.
- When the algorithms are executed:
- Feedback.
Removal algorithm (coin/counter) is executed if the contacted node was in infective state. - Blind.
Removal algorithm is executed in each cycle.
- Feedback.
Modelling Rumour Mongering
As we mentioned above there is some chance that an update will not reach all the sites, but this probability can be made arbitrarily small, because rumor spreading can be modeled deterministically.
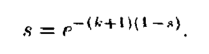
s is the proportion of nodes that do not know the update when gossip stops or that remain susceptible.
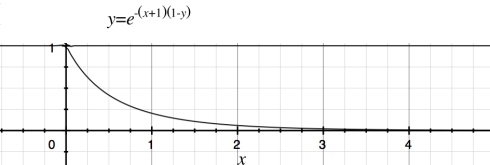
In the graph you can see how the proportion of s (y =[0,1]) converge quickly to 0 as k grows.
For example for k=1, 24% will miss the update.
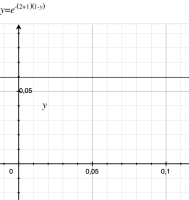
For k =2 , 6% will miss the update. For k =5, 0.25%… We can see that the spreading is very effective.
Therefore, the algorithm we use to determine when a node is in removed state or loss interest in sharing is very important.
Strategies for spreading the gossip/update
Depending on how the infective process takes place we find 3 strategies
These strategies apply for both anti-entropy and rumor mongering:
- PUSH: infective nodes are the ones sending/infecting susceptible nodes.
- infective nodes are the ones infecting susceptible nodes.
- very efficient where there are few updates.
- PULL: all nodes are actively pulling for updates. (A node can’t know in advance new updates, so it has to pull all continuously).
- all nodes are actively pulling for updates.
- very efficient where there are many updates.
- PUSH-PULL: It pushes when it has updates and it also pulls for new updates.
- The node and selected node exchange their information.
When there are a lot of updates/new info, pull is pretty good because is pretty likely that it’s going to find a node with new updates. When there are very few updates, push is better because it doesn’t introduce traffic overhead.
During the initial phase push strategies are more efficient because there are very few infective nodes, so polling requests are in vane. Pull becomes more efficient during the last phase where there are a lot of infective nodes and it’s easier to get the update, for the same reason push strategies in the last phase are not very efficient as most of the requests are sent to nodes that already know the update. That’s why there are other strategies like First-Push-Then-Pull that try to take advantage of this. [6]
In “Epidemic Algorithms for Replicated Database Maintenance.” you can find an analysis of the complexity and probability of each strategy. Although that paper is a must for gossip I’d recommend the first chapter of the book: Gossip-based Protocols for Large-scale Distributed Systems[4] because everything is very well explained.
Strategies vs models
In the SI model, there is no termination, so push is constantly sending updates even after each node has received every update. And as pull doesn’t know the list of all updates in advance, so it has to keep asking for updates.
In the SIR model, when an update/information is marked as removed is not going to be sent again.
How to measure good epidemics
In the paper [1] they proposed the following metrics:
- Residue. the remaining susceptibles when the epidemic finishes. It should be as small as possible. This is the s in the equation above.
- Traffic. The average number of database updates sent between nodes. m = total update traffic / number of sites.
- Convergence.
- tvag: average time it takes for all nodes to get an update.
- tlast: time it takes for the last node to get the update.
In the simulations we can see that with Feedback and counter the proportion of nodes that remain susceptible is smaller, although they have a bit more traffic.
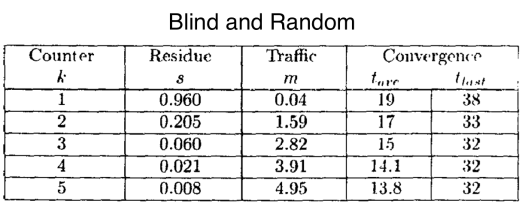
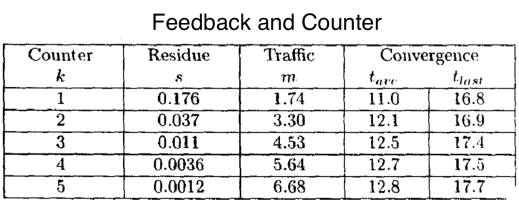
These simulations are done with push strategies, so how they behave using pull?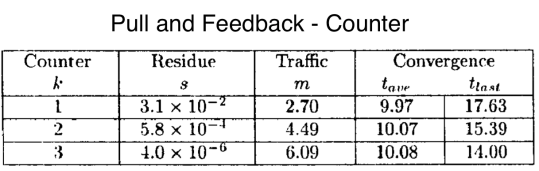
As we can see pull has a big impact in the proportion of nodes that remain susceptible, but with much more traffic
The peer sampling service
As mentioned before every Gossip protocol relies on this service, and it’s important to note that even if in a Gossip protocol we can’t find this as a proper abstraction, it is there, a gossip protocol needs a way to choose a node to exchange information and that’s the peer sampling service.
The name was coined in the fantastic paper [7] as well as its definition.
 In the figure you can see a typical algorithm for a Gossip protocol, in the line 3, there is the Peer Sampling Service.
In the figure you can see a typical algorithm for a Gossip protocol, in the line 3, there is the Peer Sampling Service.
The API of the service is really simple:
– init. (What nodes a node knows initially?)
– selectPeer or getPeer. (Return a peer/node address from the set, ideally it should be an independent uniform random sampling)
In a gossip system, ideally, a node has a table of all nodes in the system, then when a node has to gossip some information, it chooses a subset of nodes following a uniform random sample of all nodes and finally it sends the information to them. But in that case the
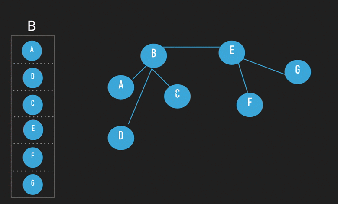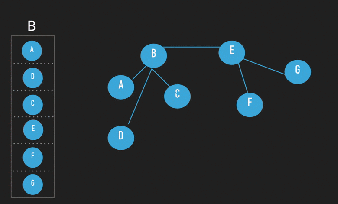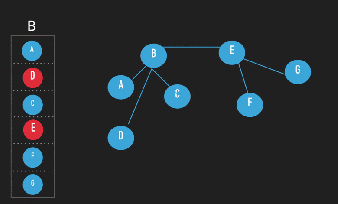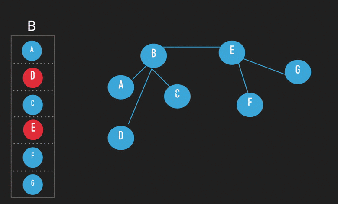 membership table would have to be maintained constantly, and in a real large system where there will be “churn” (change in the set of participating nodes due to joins, leaves, and failures) is a really hard task. So, although the Gossip protocol and the application are supposed to be scalable the selection of the peers is not [7].
membership table would have to be maintained constantly, and in a real large system where there will be “churn” (change in the set of participating nodes due to joins, leaves, and failures) is a really hard task. So, although the Gossip protocol and the application are supposed to be scalable the selection of the peers is not [7].
It’s usually assumed that the selection of peers follows a uniform random sample of all nodes in the system, and this assumption made it possible to rigorously establish many desirable features of gossip-based protocols like scalability, reliability, and efficiency. But through extensive experimental analysis has been showed that all of them lead to different peer sampling services none of which is uniformly random [7][4].
In [7] a peer sampling service based on a gossip paradigm is proposed. We can think of a Gossip protocols using this Peer sampling service as Meta-Gossip protocol, that is, a Gossip protocol that relies on a Gossip protocol 🙂
The algorithm shown in [7] follows this idea:
- initialize each node with a partial view of the nodes .
- Every time a gossip exchange happens, merge your view with the view of the node you’re gossiping with. Again take into account that in the paper there are different ways of merging.
In other words, every node maintains a relatively small local membership table that provides a partial view on the complete set of nodes and periodically refreshes the table using a gossiping procedure [7].
Both initialize and merge can work in different ways, each of these are analyzed and compared with uniform random sampling.
If you want to learn more about this I can’t recommend this paper enough [7]
Caveats
- Not very efficient. Messages can arrive several times to a node.
Gossip protocols are slow and much of its bandwidth is consumed by redundant information, for example no matter how fast we run a gossip protocol, reliable multicast protocols are going to perform better. Although are more difficult to configure and they’re not always available in all the hardware. - Latency
For example in event dissemination events don’t actually trigger the exchange, but gossip runs periodically. - The randomness inherent in many gossip protocols can make it hard to reproduce and debug unexpected problems that arise at runtime.
- Gossip protocols can’t scale well in some situations, for example a steadily increasing rate of events can exhaust the carrying capacity of the gossip information channel, and our protocol may then malfunction. The precise point at which this saturation occurs depends on many factors: the rate at which events enter the system, event sizes, gossip fanout and message sizes [3]
- The average rate at which new messages can be sent, will be roughly the inverse of the residency time: 1/log(n) [3].
References
- [1] A. Demers, D. Greene, C. Hauser, W. Irish, J. Larson, S. Shenker, H. Sturgis, D. Swinehart, and D. Terry. “Epidemic Algorithms for Replicated Database Maintenance.” In Proc. Sixth Symp. on Principles of Distributed Computing, pp. 1–12, Aug. 1987. ACM.
- [2] Kermack, W. O.; McKendrick, A. G. (1927). «A Contribution to the Mathematical Theory of Epidemics». Proceedings of the Royal Society A: Mathematical, Physical and Engineering Sciences 115 (772)
- [3] Ken Birman. The Promise, and Limitations, of Gossip Protocols. SIGOPS Oper. Syst. Rev., 41(5):8–13, October 2007
- [4] Gossip-based Protocols for Large-scale Distributed Systems. Márk Jelasity, 2013
- [5] J. Leitão, J. Pereira, and L. Rodrigues. Epidemic broadcast trees. In Huai, J. and Baldoni, R. and Yen, I., editor, IEEE International Symposium On Reliable Distributed Systems, pages 301–310. IEEE Computer Society, 2007
- [6] Ali Saidi and Mojdeh Mohtashemi. Minimum-cost first-push-then-pull gossip algorithm. IEEE Wireless Communications and Networking Conference, WCNC, pages 2554–2559, 2012
- [7] JELASITY, M., GUERRAOUI, R., KERMARREC, A.-M., AND VAN STEEN, M. 2004. The peer sampling service: Experimental evaluation of unstructured gossip-based implementations. In Middleware 2004, H.-A. Jacobsen, Ed. Lecture Notes in Computer Science, vol. 3231. Springer-Verlag, 79–98.
- [8] http://status.aws.amazon.com/s3-20080720.html
- [9] http://docs.datastax.com/en/cassandra/3.0/cassandra/architecture/archGossipAbout.html
- [10] https://www.consul.io/docs/internals/gossip.html
- [11] A Gossip-Style Failure Detection Service: Robbert van Renesse, Yaron Minsky, and Mark Hayden*; Dept. of Computer Science, Cornell University; 4118 Upson Hall, Ithaca, NY 14853
- [12] Gupta, Indranil, Chandra, Tushar D., and Goldszmidt, Germ´an S. On scalable and efficient distributed failure detectors. In Proceedings of the Twentieth Annual ACM Symposium on Principles of Distributed Computing, PODC ’01, pp. 170–179,New York, NY, USA, 2001. ACM. ISBN 1-58113-383-9. doi: 10.1145/383962.384010. URL http://doi.acm.org/10.1145/383962.384010
- [13] Montresor, A.: Intelligent Gossip. In: Studies on Computational Inteligence, Intelligent Distributed Computing, Systems and Applications, Springer, Heidelberg (2008)
- [14] On disseminating information reliably without broadcasting. Proceedings of the International Conference on Distributed Computing Systems (1987), pp. 74–81
- [15] Brenda Baker and Robert Shostak. Gossips and telephones. Discrete Mathematics, 2(3):191–193, June 1972.
- [16] http://www.inf.u-szeged.hu/~jelasity/ddm/gossip.pdf
- [17] Kermarrec, Anne-Marie, and Steen, Maarten Van, “Gossiping in distributed systems”, ACM SIGOPS Operating Systems Review, Volume 41, Issue 5, Pages: 2 – 7, 2007.
- [18] S. Voulgaris, M. Jelasity, M. van Steen, A Robust and Scalable Peer-to-Peer Gossiping Protocol,Lecture Notes in Computer Science (LNCS), vol. 2872 (Springer, Berlin/Heidelberg, 2004), pp. 47–58. doi:10.1007/b104265

Hi Félix. First of all thanks for share your knowledges about gossip also your video talks. I am trying to go deeper into the fault detection algorithms by reading the papers that you have specifically recommended to us, Gupta, Indranil, Chandra, Tushar D., and Goldszmidt, Germ´an S. failure detectors. In section 4 SCALABLE AND EFFICIENT FAILURE, why the optimum is log(PM(t))/ log(Pml), I understand that by the Accuracy requirement, we have Pml ≤ PM(T ). But I don’t understand why the probabilities are divided by log. What is the target of dividing between logarithms?